



爬虫技术
一、什么是网络爬虫:
网络爬虫(web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
二、爬虫分类:
主要分为以下三类:
1、小规模,数据量小,爬取速度不敏感;对于这类网络爬虫我们可以使用Requests库来实现,主要用于爬取网页;
2、中规模,数据规模较大,爬取速度敏感;对于这类网络爬虫我们可以使用Scrapy库来实现,主要用于爬取网站或系列网站;
3、大规模,搜索引擎,爬取速度关键;此时需要定制开发,主要用于爬取全网,一般是建立全网搜索引擎,如百度、Google搜索等。
在这三种中,我们最为常见的是第一种,大多数均是小规模的爬取网页的爬虫。
Robots协议:
从爬虫的限制中,可以看到Robots协议是防止爬虫的一种手段。robots.txt是一个协议,是搜索引擎中访问网站的时候要查看的第一个文件。它告诉蜘蛛程序在服务器上什么文件是可以被查看的。
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;
三、爬虫原理
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。
然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;
所以一个完整的爬虫一般会包含如下三个模块:
l 网络请求模块
l 爬取流程控制模块
l 内容分析提取模块
网络请求
我们常说爬虫其实就是一堆的http(s)请求,找到待爬取的链接,然后发送一个请求包,得到一个返回包,当然,也有HTTP长连接(keep-alive)或h5中基于stream的websocket协议,这里暂不考虑;
所以核心的几个要素就是:
l url
l 请求header、body
l 响应herder、内容
四、简单实例
网络爬虫的第一步就是根据 URL,获取网页的 HTML 信息。在 Python3 中,可以使用urllib.request和requests进行网页爬取。
urllib 库是 python 内置的,无需我们额外安装,只要安装了 Python 就可以使用这个库。requests 库是第三方库,需要我们自己安装。使用 requests 库获取网页的 HTML 信息。
requests 库的基础方法如下:
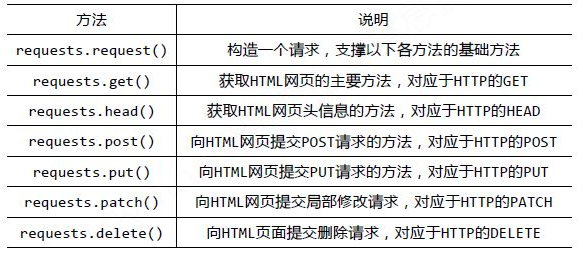
首先,让我们看下 requests.get()方法,它用于向服务器发起 GET 请求,不了解 GET 请求没有关系。我们可以这样理解:get 的中文意思是得到、抓住,那这个 requests.get()方法就是从服务器得到、抓住数据,也就是获取数据。让我们看一个例子(以 www.gitbook.cn 为例)来加深理解:
1. 1# -*- coding:UTF-8 -*-
2. 2import requests
3. 3
4. 4if __name__ == '__main__':
5. 5 target = 'http://gitbook.cn/'
6. 6 req = requests.get(url=target)
7. 7 print(req.text)
requests.get()方法必须设置的一个参数就是 url,因为我们得告诉 GET 请求,我们的目标是谁,我们要获取谁的信息。运行程序看下结果:
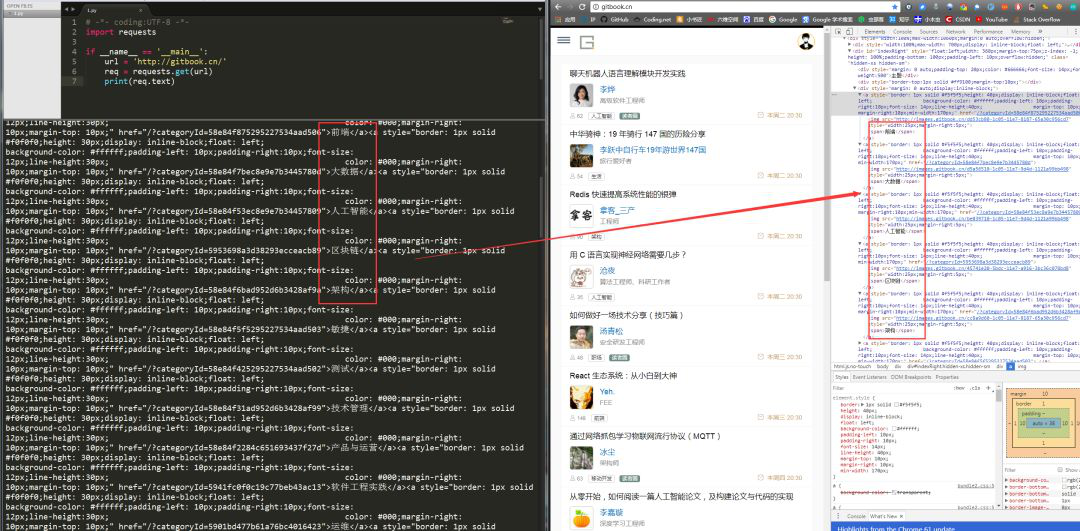
左侧是我们程序获得的结果,右侧是我们在 www.gitbook.cn 网站审查元素获得的信息。我们可以看到,我们已经顺利获得了该网页的 HTML 信息。这就是一个最简单的爬虫实例,可能你会问,我只是爬取了这个网页的 HTML 信息。





 写留言
写留言
 收藏
收藏
 微博分享
微博分享
 微信
微信
 朋友圈
朋友圈
 QQ
QQ
 微博
微博
 QQ空间
QQ空间
 复制链接
复制链接





















