




一些目前最热的神经网络,例如卷积神经网络、循环神经网络、强化学习、生成对抗网络等,它们有很多神奇的地方,在实际中也得到了相当广泛的应用。但神经网络也好,深度学习也好,都不是万能的,它们有其自身的局限性。
神经网络的一个局限性是,需要依赖特定领域的先验知识,也就是需要特定场景下的训练,说白了就是神经网络只会教什么学什么,不会举一反三。神经网络的这个局限性,是因为神经网络的学习本质上就是对相关性的记忆,也就是说神经网络将训练数据中相关性最高的因素作为判断标准。
打比方说,如果一直用各个品种的白色狗来训练神经网络,让它学会「这是狗」的判断,神经网络会发现这些狗最大的相关性就是白色,从而得出结论:白色等于狗。在这种情况下,让这个神经网络看见一只白猫,甚至一只白兔子,它仍然会判断为狗。机器学习的这种呆板行为,用专业术语描述叫「过度拟合」。如果想让神经网络变得更聪明,就必须用各种颜色、各个品种、是否穿衣服等各种场景下的狗来训练神经网络,如此它才有可能发现不同的狗之间更多的相关性,从而识别出更多的狗。人类则不同,一个两三岁智力发育正常的孩子,在看过几只狗之后,就能认出这世上几乎所有的狗了。无须大量标注数据和特殊场景的训练,只需要少量的数据,人脑就可以自己想清楚这个过程。在这方面,目前的神经网络和人脑相比,还有很大的差距。主要的发展瓶颈存在以下三点:
一、需要大量标注数据
深度学习能够实现的前提是大量经过标注的数据,这使得计算机视觉领域的研究人员倾向于在数据资源丰富的领域搞研究,而不是去重要的领域搞研究。
虽然有一些方法可以减少对数据的依赖,比如迁移学习、少样本学习、无监督学习和弱监督学习。但是到目前为止,它们的性能还没法与监督学习相比。
二、过度拟合基准数据
深度神经网络在基准数据集上表现很好,但在数据集之外的真实世界图像上,效果就差强人意了。
一个用ImageNet训练来识别沙发的深度神经网络,如果沙发摆放角度特殊一点,就认不出来了。这是因为,有些角度在ImageNet数据集里很少见。在实际的应用中, 如果深度网络有偏差,将会带来非常严重的后果。
三、对图像变化过度敏感
深度神经网络对标准的对抗性攻击很敏感,这些攻击会对图像造成人类难以察觉的变化,但可能会改变神经网络对一个物体的认知。
而且,神经网络对场景的变化也过于敏感。比如下面的这张图,在猴子图片上放了吉他等物体,神经网络就将猴子识别成了人类,吉他识别成了鸟类。
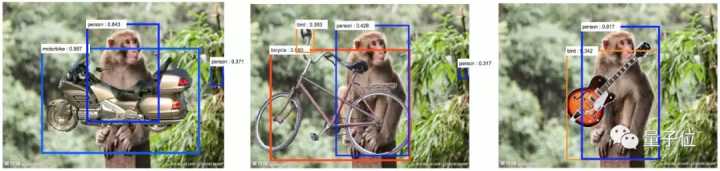
背后的原因是,与猴子相比,人类更有可能携带吉他,与吉他相比,鸟类更容易出现在丛林中。这种对场景的过度敏感,原因在于数据集的限制。对于任何一个目标对象,数据集中只有有限数量的场景。在实际的应用中,神经网络会明显偏向这些场景。
对于像深度神经网络这样数据驱动的方法来说,很难捕捉到各种各样的场景,以及各种各样的干扰因素。
想让深度神经网络处理所有的问题,似乎需要一个无穷大的数据集,这就给训练和测试数据集带来了巨大的挑战。
而在有限的数据集上训练/测试出来的模型,会缺乏现实意义:因为数据集不够大,代表不了真实的数据分布。
那么,就有两个新问题需要重视:
1、怎样在有限的数据集里训练,才能让AI在复杂的真实世界里也有很好的表现?
2、怎样在有限的数据集里,高效地给算法做测试,才能保证它们承受得了现实里大量数据的考验?





 写留言
写留言
 收藏
收藏
 微博分享
微博分享
 微信
微信
 朋友圈
朋友圈
 QQ
QQ
 微博
微博
 QQ空间
QQ空间
 复制链接
复制链接





















